Notes from Expert SQL Server Transactions and Locking by Korotkevitch, Dmitri
1.1 表的内部结构
首先借用书中的图来说明表的内部结构。
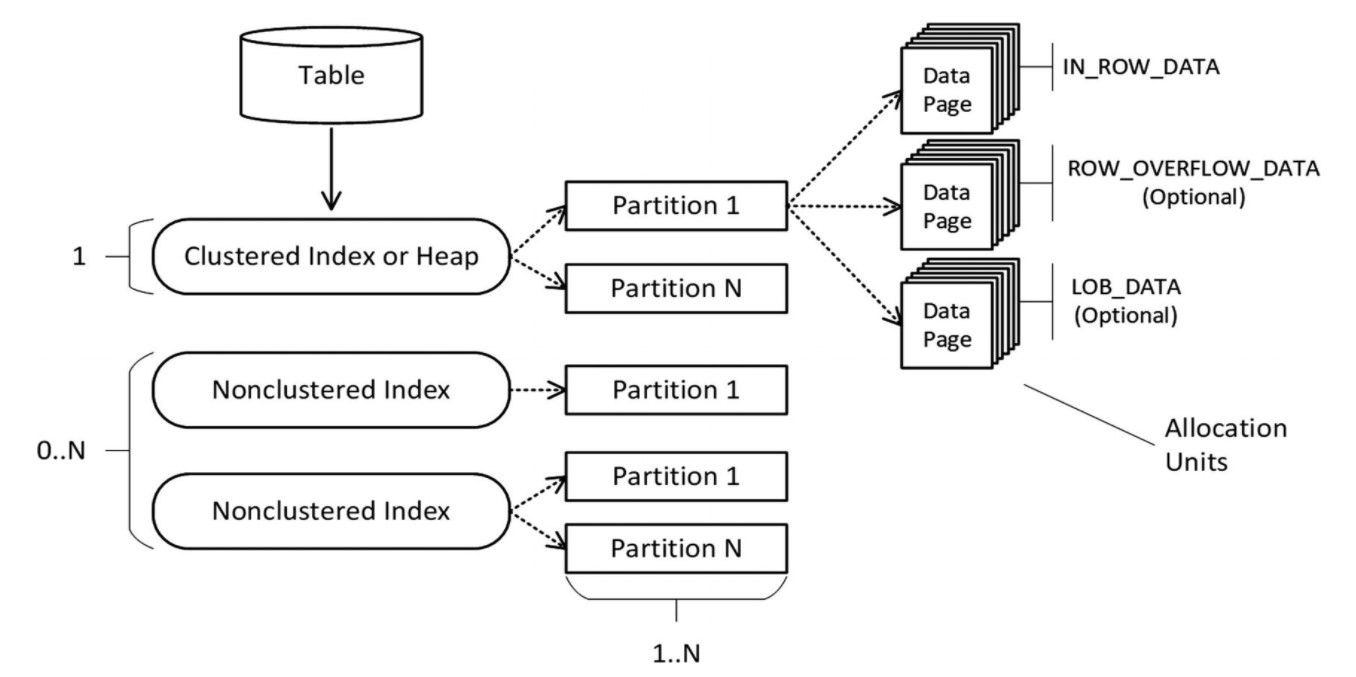
首先,表中存储的数据要么根据聚集索引键的值进行排序,要么完全无序(成为堆表或者堆)。
除了一个聚合索引/堆,每张表可能拥有一组非聚合索引。每个索引都是独立的数据结构,可以存储一份数据副本。(因此,如果有一列被包含三个这样的非聚合索引中,那它的数据会被保存四份,一份在聚集索引中,三份在非聚集索引中。)
每个索引包含一到多个分区。每个分区也是一个独立的内部数据结构。
每个分区内包含许多数据页。实际数据以数据行的形式储存在8KB的数据页中。数据页的结构如下图所示。
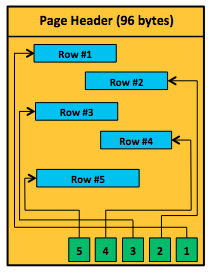
每个数据页的大小为8KB,即8192 bytes。其中,固定96 bytes的大小为页头。接下来的8060 bytes是用户可以使用的空间用来记录数据,以行的形式储存。剩下的36 bytes是行偏移数组表,自下而上保存槽数组指针或转发行返回指针。
(个人理解:后面两部分的大小不是固定的,如果每条数据的长度小,没有占满8060 bytes的空间,可能记录的数据条数会多,而使得偏移数组表的大小超过36 bytes,只要总大小符合就行。以后再确认是否如此?)
···对于可变长度的数据,可能不能直接写在数据行(in-row)中,SQL Server会将其分成多行(out-row)储存在不同数据页中,再通过in-row pointers来引用。
···超过8000 bytes的可变长度数据会被储存在LOB_DATA (large objects)数据页中。
SQL Server会将8页组成一个64KB的单元,称为扩展(extent)。
···扩展有两种:mixed extents(储存不同对象的数据)和uniform extents(储存同一对象的数据)。默认情况下,在新对象创建时,SQL Server将前八个对象页储存在mixed extents。之后的储存则通过uniform extents实现。
SQL Server使用一种特殊的页,称为分配映射(allocation maps),来追踪extent和page的使用。Index Allocation Maps(IAM)使用bitmap来指示extent是否属于一个特定的分配单元(allocation unit)。
每一页IAM覆盖了约64000 extents / 约4GB数据。
1.2 堆表
堆表(heap table)指的是没有聚集索引的表。堆表中的数据是无序的。SQL Server不保证也不维护堆表中数据的顺序。
在堆表中插入数据的原则是尽可能把一页的空间填满。SQL Server使用Page Free Space(PFS)来追踪每页中剩余空间的数量,方法是使用3 bits来指示这一页的状况(包括empty, 1% to 50%, 51% to 80%, 81% to 95%, 95% above full)。
在堆表中查询数据:SQL Server会使用IAM页来找到该表的页和扩展。
在堆表中更新数据:SQL Server会优先在同一页中更新。如果没有可用空间空余了,会将新的内容写到另一页(称为forwarded row),并将原来的一行替换为一个16 bytes的行(称为forwarding pointer)。
···使用 forwarding pointer的两个原因:避免非聚集索引键更新,并尽可能少地做重复读。但同时也带来了更多的IO操作。
堆表可以用于尽快导入大量数据来建立环境的时候。因为在堆表中插入数据通常比在聚集索引的表中插入数据更快。但是在日常运行中,堆表的性能不如聚集索引的表,原因是它的空间控制方式以及额外的IO操作。
1.3 聚集索引和B树
聚集索引指的是表中的数据按照索引键的排序按顺序储存。
B树:一种平衡的多叉树,其储存的数据按照索引键的值进行排序,叶级和中间级的数据页通过双向链表来连接。(具体介绍网络上很多,这里略了…)
SQL Server总是会维护索引中数据的顺序,将新插入的行放到属于它们的地方。如果一个数据页没有足够的剩余空间,SQL Server会分配一个新的页,并将行写到上面,调整双向链表中的pointer来维护索引的逻辑排序。这个操作称为分页(page split),但也会导致索引碎片。
分页也有可能在数据修改的时候发生。此时SQL Server不使用B树索引的forwarding pointer。如果一次更新不能在原地完成,SQL Server会通过分页,将已更新的和随后的行移动到其它页上。不过,索引的排序依然通过页面指针来维护。
SQL Server可以用三种方式从索引来读取数据:
(1)按分配顺序扫描(allocation order scan)。SQL Server通过IAM页来获取表数据。这种方法可能会引入数据一致性的问题,因此很少使用。
(2)按顺序扫描(ordered scan)。
以上两种方法被称为索引检索(index scan)操作。
(3)索引搜寻(index seek)。
索引搜寻的操作有两种。第一种叫点搜寻(point-lookup),SQL Server会搜寻并返回单一行。另一种叫范围搜寻,要求SQL Server找到键的最低或最高值,并检索整个范围内的所有行。
索引搜寻比索引检索效率高,因为SQL Server只处理行和页的子集。
另外,关系型数据库中有一个概念叫SARGable predicates(Search Argumentable),指如果索引存在的话,SQL Server可以通过索引搜寻来实现操作。也就是说,只要SQL Server可以判断需要处理的索引键值或者范围,这个predicate就是SARGable的。因此,要尽可能使用SARGable predicate来写查询语句。
SARGable 包含以下操作=, >, >=, <, <=, IN, BETWEEN, LIKE (在前缀匹配的时候). 非SARGable操作符包括NOT, <>, LIKE (非前缀匹配的时候), and NOT IN。
1.4 复合索引
复合索引中的数据按每列从最左到右列进行排序。
复合索引的SARGability取决于最左边索引列的SARGability
1.5 非聚集索引
聚集索引指定了数据行在表中的排列方式,非聚集索引则为一列或一组列定义单独的排序顺序,并将它们保留为单独的数据结构。
非聚集索引的叶级根据索引键的值来进行排序。叶级的每一行都包含了键值以及行id(row-id)的值。对于堆表来说,row-id值是这一行的物理地址,通过“文件:页数:槽”的地址来定义,其中槽指明这一行在数据页中的地址。
对于带聚集索引的表,row-id代表该行聚集索引键的值。如果一个表定义有聚集索引,那非聚集索引就不储存该行物理地址的信息,而是储存聚集索引键的值。
与聚集索引一样,非聚集索引的中间级和根级也从它们引用的级别中每页存储一行。该行由页面中键的物理地址和最小值组成。此外,对于非单一索引,它也会存储这样一行的row-id。
查找数据所需要的I/O操作的数量可以通过以下公式来计算:(非聚集索引的级数)+(从非聚集索引的页级读的页数)+(找到的行数)*(聚集索引的级数)。
SQL Server 在选择非聚集索引时非常保守,因为它可能导致大量的键或 RID 查找操作。非聚集索引存储索引列中的数据副本,从而引入更新开销。当更新一列时,SQL Server 需要在这一列存在的每个索引中更新它们。同样,每个插入或删除操作都需要 SQL Server 在每个非聚集索引 B 树上执行它。
因此,要尽量避免在系统中创建不必要的非聚集索引。
1.6 包含列的索引
非聚集索引中的行要比聚集索引中的小。非聚集索引使用更少的数据页,也因此效率更高。因此,只要不要求键或者RID的查找,SQL Server即使在需要选择大量的行的时候也会选择非聚集索引。
(个人理解:聚集索引的叶级储存实际数据,但非聚集索引的叶级仍然是索引节点,包含了一个指向相应数据块的指针,还需要再通过聚集索引来获取数据。因此,非聚集索引的行一般小于聚集索引,在只需非聚集索引就能得到所需的数据列的时候效率更高。在这种情况下,即使需要选择很多行,也会使用非聚集索引)
如果一次查询所需的数据都在非聚集索引,不需通过二级索引查到主键之后再去查询数据,SQL Server就不会执行键或者RID查找。这样的索引称为覆盖索引(covering indexes)。
在优化中多使用覆盖索引可以提高查询效率,减少键或RID查找的次数。可以通过INCLUDE来包含所需要的列来实现。
如果查询引用的所有列都在索引中,SQL Server就可以从非聚集索引B树的叶级获取所有数据,而不用执行键或者RID查找。无论从中选择多少行,它都可以使用索引。
但是覆盖索引也会有代价。它在索引的维护中引入额外的开销,增加数据库的体积。另外,在查询扫描所有或部分索引的时候也需要读更多的页。因此,在大范围的扫描时候也不适合使用。
第一章结束,看英文的技术书还是很头疼,自己翻译的也很不通顺,以后找机会再回头精炼一下语句吧,先抓紧把整本书过一遍。其中有些理解的内容参考了网络上的资料,因为直接引用的不多就暂不一一列出了(科研素质还是不行),在此先说一句道歉与感谢。